


Введение в контекст проблемы
10 лет я наблюдаю, исследую и разбираюсь в процессах управления. Одна из основных ошибок, которую я встречаю, — попытка управлять отдельно взятым событием.
Руководитель видит эффективного сотрудника — хвалит его по последним методологиям «похвалы».
Руководитель видит неэффективного сотрудника, открывает «50 татуировок» — ищет ответ, применяет его к сотруднику.
Наступает завтра, показатели неэффективного сотрудника не поменялись, как и послезавтра.
Хорошо,
- поставим цели,
- дадим наставника,
- составим план развития,
- будем «лечить».
Наступает послезавтра — показатели неэффективного сотрудника не поменялись или поменялись в определенном диапазоне, доступном ему.
Что если для каждого сотрудника есть верхний и нижний диапазон его эффективности, и он зависит не от локальных методов и действий руководителя.
Иннокентий и Григорий работают в отделе продаж и принимают звонки.
Иннокентий с диапазоном конверсий от 3% до 8% (на картинке слева) и Григорий с диапазоном от 8% до 25% (на картинке справа).
Локальные действия для первого сотрудника могут привести его к нижнему диапазону лучшего сотрудника. Но никакие действия не приведут его за его максимальный диапазон эффективности.
Иннокентий

Григорий
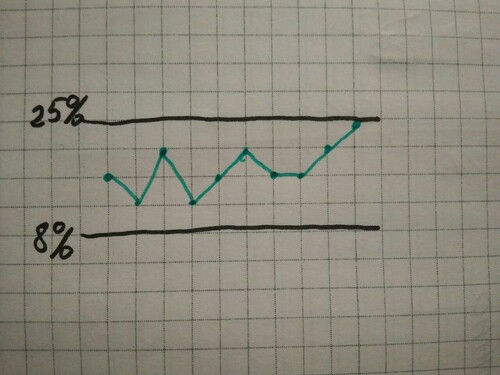
Таким образом, инвестиции в Иннокентия выведут его на уровень нижней границы результатов Григория.
Сейчас я не буду давать математических расчетов, просто примерьте на свою рабочую ситуацию.
Как часто вы инвестируете в локальные корректировки сотрудников и сколько из этого времени досталось Григорию?
Как определить на этапе найма, у нас Иннокентий или Григорий проходит собеседование?
Постановка задачи для исследования
Компания работает в сфере услуг. В компании есть кол-центр численностью 30 человек, которые принимают входящие звонки. Цель звонка — запись на визит в офис компании. Необходимо найти факторы, с помощью которых можно предсказать будущую эффективность сотрудника.
Инструмент для исследования — линейная регрессия.
Имена сотрудников, а также значимые данные были переименованы, т.к. попадают под NDA.
Подготовка данных для исследования
В ходе подготовки исследования подготовил два набора данных. Статистика по звонкам каждого сотрудника кол-центра. Умышленно здесь не буду приводить описание всего процесса подготовки. Отмечу, что в ходе подготовки набора данных мною были созданы дополнительные переменные — процесс называется “Feature engineering”.
Feature engineering — процесс создания дополнительных полезных переменных.
У вас есть
- звонки в кол-центре в штуках,
- оборот по каждому сотруднику в рублях.
Чтобы сравнить сотрудников, вы можете создать дополнительную переменную — оборот в рублях / количество звонков.
Таким образом вы сможете сравнить сотрудников по эффективности. Такую метрику мне подсказал Никита Шейн из IT-Agency.
Второй этап — подготовка категориальных данных по сотрудникам. С помощью таких данных как
- возраст,
- опыт работы,
- время до работы
мы попробуем найти факторы, влияющие на эффективность сотрудника. Привожу итоговый список переменных.
Количественные данные по сотрудникам:
- среднее время звонков,
- количество записей,
- сумма продаж,
- город как источник звонка,
- средний чек = сумма продаж / количество,
- среднее время звонка = сумма разговоров / количество успешных входящих звонков,
- запись на звонок = отношение количества записей к количеству звонков,
- оборот на звонок = отношение суммы записей к количеству звонков,
- возрастная группа = группы сотрудников в диапазоне от 20 — 30 лет, 30 — 40 и 40 — 60 лет.
Категориальные данные по сотрудникам:
- возраст,
- коммуникационный тест DISC,
- источник привлечения HH.ru или друзья / знакомые,
- время до работы,
- опыт работы в продажах до устройства в компанию,
- удаленность от работы в минутах.
Коммуникационный DISC тест
Для сотрудников я провел тестирование по DISC типологии. Цель тестирования —обогатить категориальные данные исследования и проверить мою гипотезу, что группа с высоким «I» стилем будет иметь связь с результатами по продажам.
Ниже привожу описание каждого стиля. Нижняя часть круга — люди, более склонные к контактам и коммуникации, верхняя — люди, более склонные к логическим суждениям и фокусирующиеся на задачах.
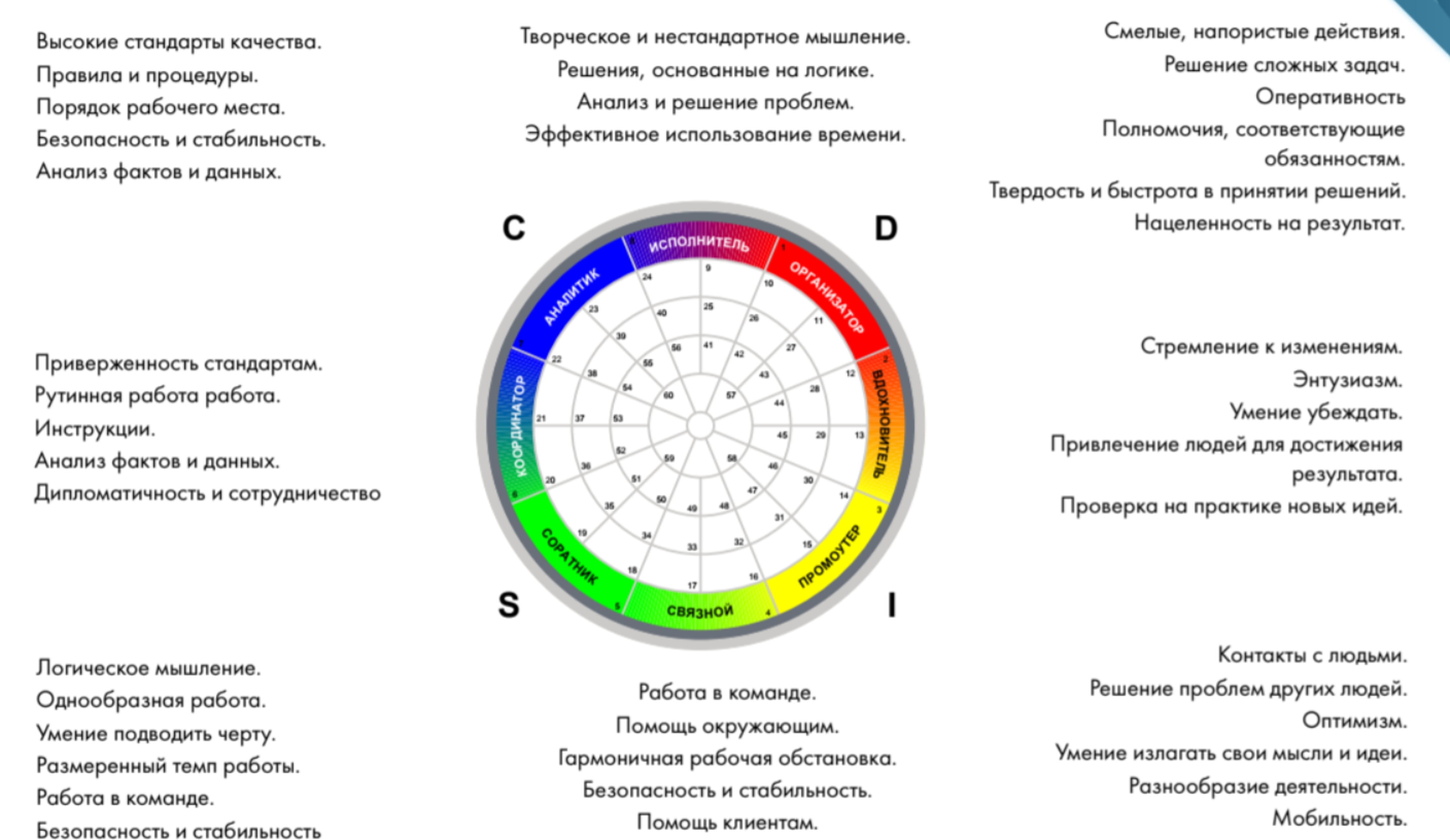
В итоге такого тестирования у меня получились следующие данные:
Петя — D: 18, I: 4, C: 3, S: 2.
Чтобы избежать переобучения при построении модели перевел данные в следующие вид:
Петя — D: высокий, I: низкий, С: низкий, S: низкий.
Выбор переменной для исследования
В качестве целевой переменной для анализа выбрал оборот на звонок. Хороший показатель, чтобы оценить сотрудника кол-центра. Он содержит в себе информацию о качестве принимаемых звонков. Такой показатель, как средний чек, содержит в себе информацию о том, как дорого продает сотрудник, и сейчас нам не подходит.
Перед построением модели провел нормирование данных, т.к. гистограмма распределения оборота на звонок имела ненормальное распределение.
Построение модели
Модель построил в R-studio с помощью линейной регрессии. Благодаря регрессии можно получить интерпретацию исследуемых факторов. Теперь рассмотрим статистическую выкладку по модели. Часть данных я не могу раскрыть, поэтому они затерты красным. Объект интереса — первые 4 фактора. Выделил в красную рамку.
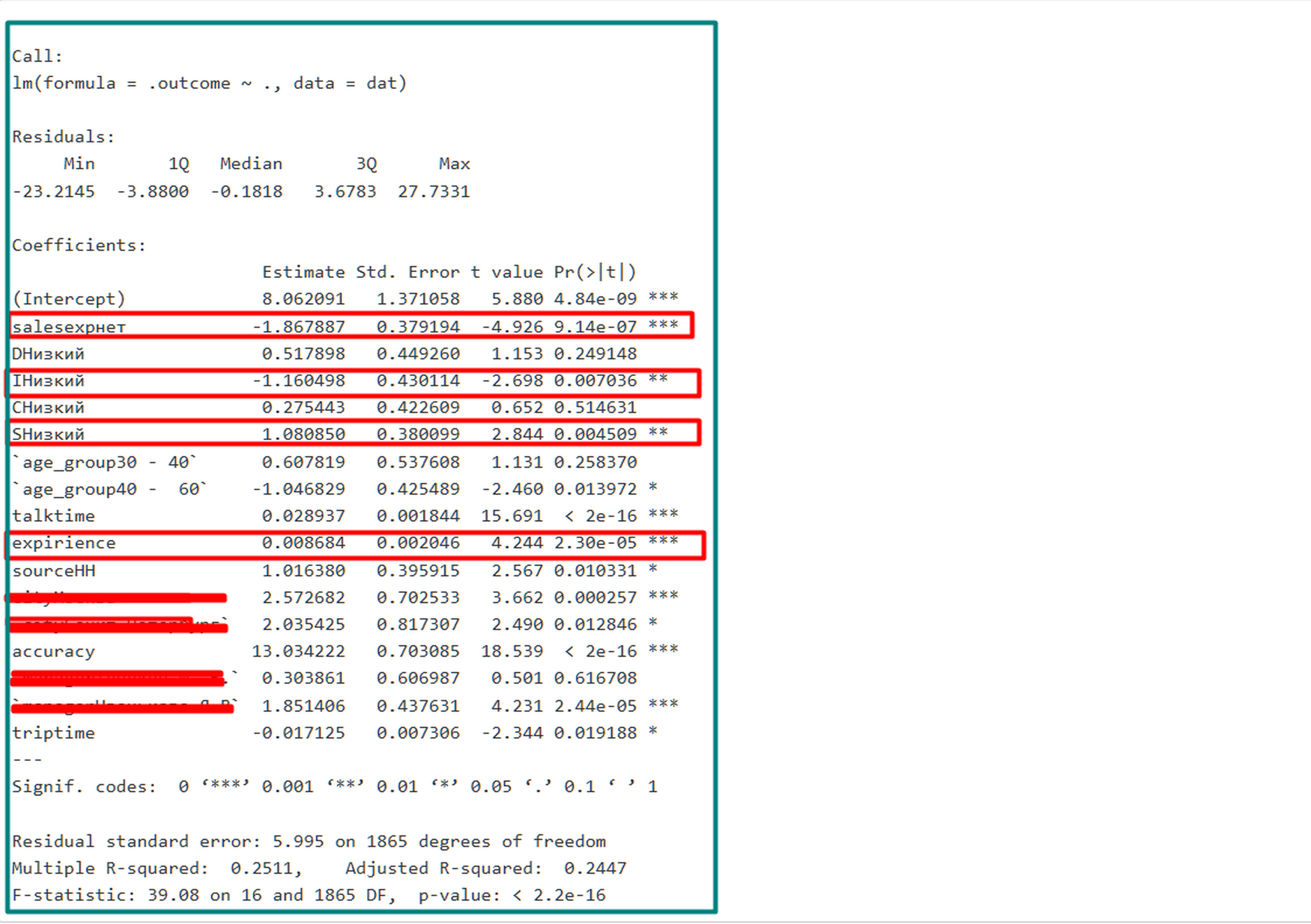
Отсутствие
опыта продаж
до начала работы
отрицательно влияет
на оборот
на звонок.
Низкий I
по стилю
коммуникации
отрицательно влияет на оборот
на звонок.
Низкий S
по стилю
коммуникации
положительно влияет на оборот
на звонок.
Опыт работы
в текущей
должности
чем больше опыт в неделях, тем выше оборот на звонок.
Таким образом, мы получили 4 значимых фактора, на основе которых можем предсказать, будет сотрудник более эффективен или менее в должности в разрезе показателя «оборот на звонок». Далее разберу еще одни показатель, который поможет укрепить мысль о важности системных действий в управлении.
Связь времени разговора с оборотом
на звонок
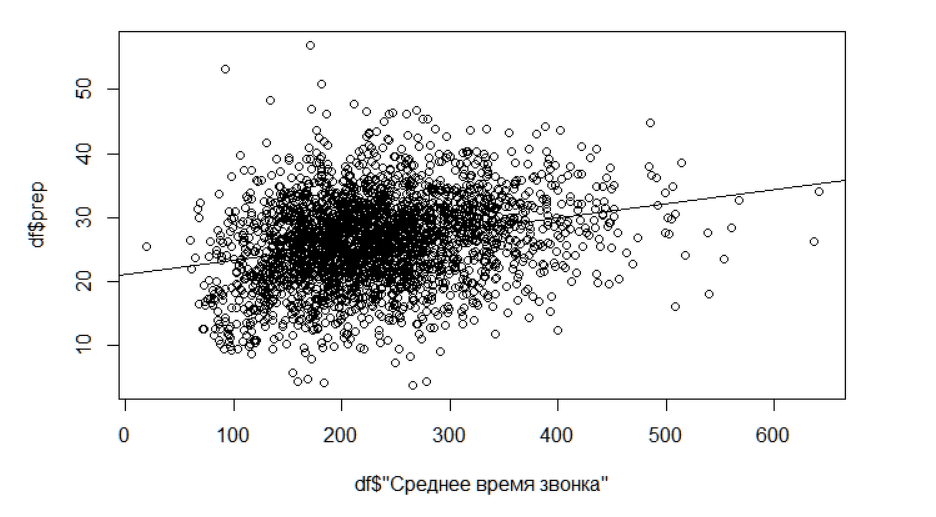
Показатель “talktime” — время разговора с клиентом. Чем выше время разговора с клиентом у оператора, тем выше оборот на звонок.
Ниже на графике видим линейную зависимость, которая подтверждает результат. Данные по всей команде операторов. По оси X — среднее время разговора, Y — нормализованный оборот на звонок.
Сотрудники с высоким I стилем коммуникации
Справа сравнение двух групп. Сотрудники с высоким I и низким I стилем коммуникации.
Как видим, время разговора первой группы выше. Что дает нам право строить гипотезу, что, нанимая сотрудников с I стилем, мы будем иметь более высокое время разговора, а соответственно, более высокий оборот на звонок.

Сотрудники с высоким I и
низким I стилем коммуникации.
Резюме
Руководителю будет полезно искать системные причины для управления результатами деятельности своей команды, подразделения, бизнес единицы.
Выше я привел один из простых примеров анализа. Анализ можно углубить и расширить, используя более сложные методы машинного обучения.
Мы выяснили, что можно подбирать персонал в кол-центр на основе методов машинного обучения и DISC типологии. Хотя я и не привел достаточных цифровых показателей добавленной стоимости внедрения такого метода. Такой расчет — это индивидуальная задача под каждую компанию.
Источник — статья в блоге Артема Николаева

Связанные статьи
- Как с помощью DISC создать эффективную, слаженную команду
- Чек-лист: эффективны ли вы как руководитель в условиях удалённой работы
- Как использовать DISC при формировании кадрового резерва
- Командообразование в стиле «DISC» для начинающих и бывалых руководителей
- Google потратил годы, исследуя эффективных руководителей. Теперь они обучают новых менеджеров этим 6 вещам.

Информационные продукты на данной странице рассчитаны на возраст 18+
‣ Типология DISC
‣ Эмоциональный интеллект EQ
‣ Оценка 360 градусов
‣ Тесты ценностей. Корпоративная культура
‣ HR функция
‣ Оценка персонала
‣ Оценка компетенций
‣ Профиль должности
‣ Индивидуальный план развития ИПР и Кадровый резерв
‣ Команда
‣ Развитие лидерства и управленческих компетенций
‣ Мотивация
‣ Выгорание
‣ Психодиагностика
авторизуйтесь